Playing for Benchmarks




Introduction
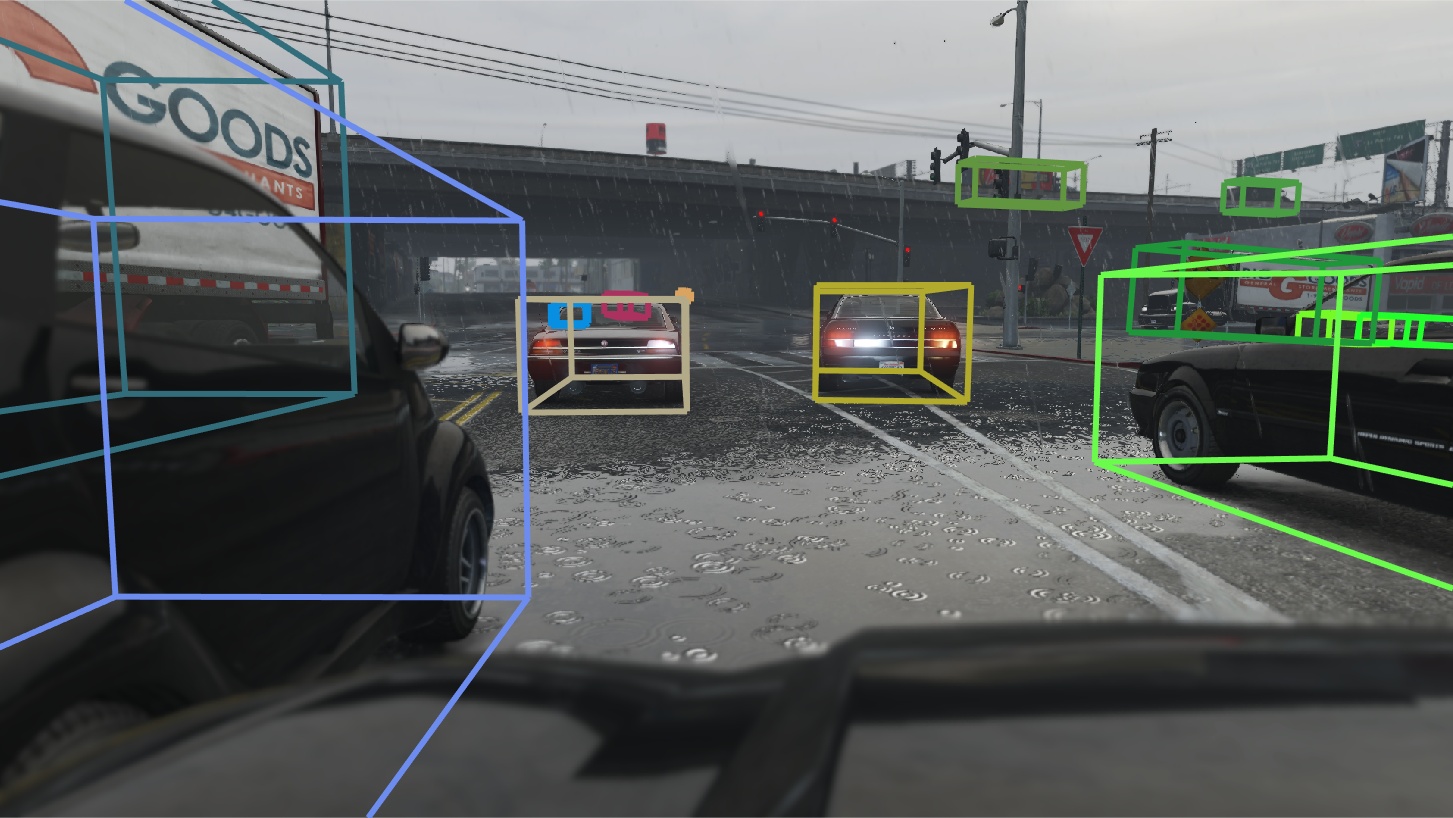
We present a benchmark suite for visual perception. The benchmark is based on more than 250K high-resolution video frames, all annotated with ground-truth data for both low-level and high-level vision tasks, including optical flow, semantic instance segmentation, object detection and tracking, object-level 3D scene layout, and visual odometry. Ground-truth data for all tasks is available for every frame. The data was collected while driving, riding, and walking a total of 184 kilometers in diverse ambient conditions in a realistic virtual world. To create the benchmark, we have developed a new approach to collecting ground-truth data from simulated worlds without access to their source code or content. We conduct statistical analyses that show that the composition of the scenes in the benchmark closely matches the composition of corresponding physical environments. The realism of the collected data is further validated via perceptual experiments. We analyze the performance of state-of-the-art methods for multiple tasks, providing reference baselines and highlighting challenges for future research.
Paper

BibTeX
Please cite our work if you use code or data from this site.
@InProceedings{Richter_2017,
title = {Playing for Benchmarks},
author = {Stephan R. Richter and Zeeshan Hayder and Vladlen Koltun},
booktitle = {{IEEE} International Conference on Computer Vision, {ICCV} 2017, Venice, Italy, October 22-29, 2017},
pages = {2232--2241},
year = {2017},
url = {https://doi.org/10.1109/ICCV.2017.243},
doi = {10.1109/ICCV.2017.243},
}